

How do you strike the right balance between rules-based analytics, statistical analytics, and machine learning when it comes to compliance monitoring? This is a question that comes up often when we're speaking with Compliance leaders focused on compliance with anti-corruption laws such as the FCPA and UK Bribery Act, so we wanted to share some tips to help differentiate these approaches.
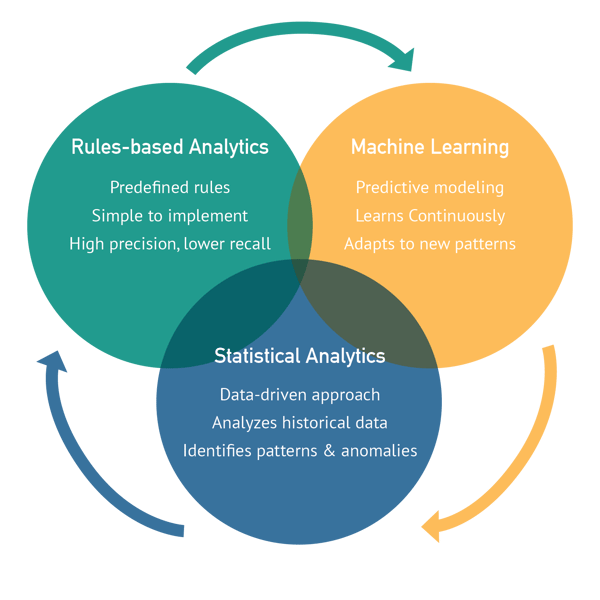
Rules-based analytics are typically used to detect known fraud or suspicious behavior patterns. They rely on a set of predefined rules that trigger an alert when specific criteria are met. Advanced custom risk-based rules that are aligned with key-risk indicators are essential. However, relying solely on standard rules-based analytics may lead to missed opportunities as it is only effective in detecting known patterns of inappropriate activity.
Pros:
-
Easy to understand and implement
-
Highly specific to the rules established, meaning that it can be highly precise in identifying potential compliance issues
-
Minimal false positives since it relies on predetermined rules
Cons:
-
Limited in scope, as it can only identify issues that are explicitly defined in the rules
-
Can be rigid and inflexible, as it requires manual intervention to update rules
-
Limited in its ability to detect complex or emerging compliance risks
Statistical analytics are used to identify anomalies in data that may indicate suspicious behavior. Unlike rules-based analytics, statistical analytics can detect unknown patterns of fraudulent activity. Combining statistical analytics with rules-based analytics can improve the accuracy of detection. However, relying solely on statistical analytics may lead to high false positives.
Pros:
-
Can identify patterns and anomalies in data that may not be apparent through rules-based analytics
-
Can be more flexible than rules-based analytics, as it can adapt to changing data and trends
-
Can be automated, which reduces the need for manual intervention
Cons:
-
May generate false positives or negatives, as it relies on statistical models that can be prone to errors
-
Requires significant expertise and resources to develop and maintain effective models
-
May require significant data cleaning and preparation to be effective
Machine learning algorithms learn from data to identify patterns and anomalies. However, it requires a significant amount of data from which to learn (the smaller the sample, the more unreliable the algorithm will be). There is a risk of false negatives (e.g., the model fails to identify corruption) and bias in the algorithm (e.g., the model is trained on only one region or one industry).
Pros:
-
Can learn from data and improve over time, making it more effective at identifying potential compliance issues
-
Highly adaptable and flexible, able to handle complex and changing data
-
Can automate many aspects of compliance monitoring, reducing the need for manual intervention
Cons:
-
May generate false positives or negatives if the model is not trained properly
-
Requires significant expertise and resources to develop and maintain effective models
-
May be opaque, making it difficult to explain the reasoning behind the results
When it comes to compliance monitoring, it is essential to strike the right balance between rules-based analytics, statistical analytics, and machine learning to ensure effective monitoring while minimizing the risk of false positives and negatives. Here are some considerations to help you achieve this balance:
-
Understand the strengths and limitations of each approach: Rules-based analytics rely on predetermined rules to identify potential compliance issues, while statistical analytics use statistical models to identify patterns and anomalies in the data. Machine learning, on the other hand, uses algorithms to learn from data and improve over time. Each approach has its strengths and limitations, and understanding them will help you determine which approach is best suited for your compliance monitoring needs.
-
Consider the complexity of the data: If the data is relatively simple and easy to interpret, rules-based analytics may be sufficient. However, if the data is complex and difficult to analyze, statistical analytics or machine learning may be more effective.
-
Determine the level of human involvement required: Rules-based analytics typically require manual intervention to update rules, while statistical analytics and machine learning can automate much of the process. If you have limited resources or want to minimize the risk of human error, machine learning may be the best choice.
-
Evaluate the risk tolerance of your organization: If your organization has a low risk tolerance, you may want to prioritize rules-based analytics to minimize the risk of false positives and negatives. However, if your organization is comfortable with a higher level of risk, statistical analytics or machine learning may be appropriate.
Start with rules-based analytics to identify known patterns of fraud and suspicious behavior. Then, incorporate statistical analytics to detect unknown patterns of fraud. Finally, use machine learning to learn from the data and improve detection accuracy continuously.
By leveraging a combination of rules-based analytics, statistical analytics, and machine learning, you can enhance your transaction monitoring program's effectiveness and reduce false positives, ultimately protecting companies from financial crimes.
To learn about Lextegrity and our many compliance solutions, reach out to us for a consultation today.




